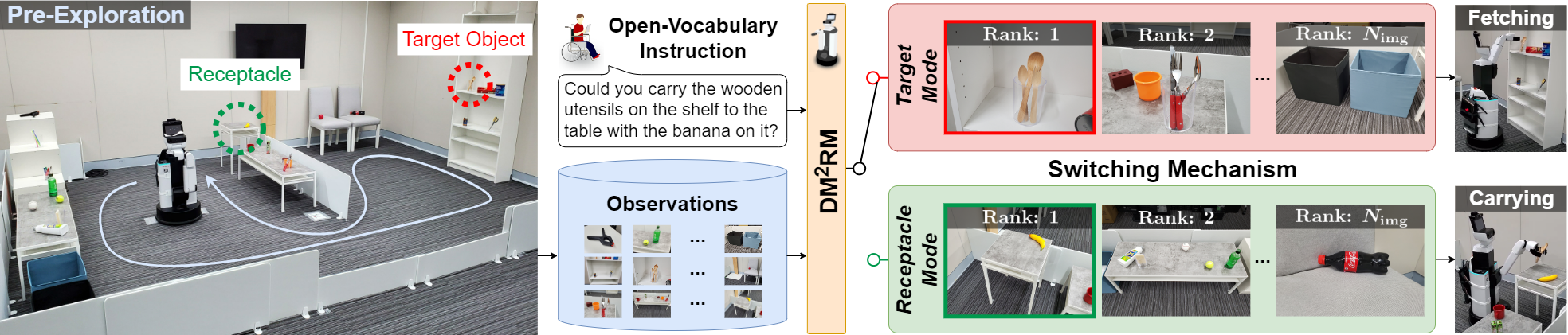
In this study, we aim to develop a domestic service robot (DSR) that, guided by open-vocabulary instructions, can carry everyday objects to the specified pieces of furniture. Specifically, we focus on an approach that retrieves images of the target objects and receptacles from images of an environment collected through pre-exploration. Few existing methods handle object manipulation tasks with open-vocabulary instructions in the image retrieval setting, and most do not identify both the target objects and the receptacles. We propose the Dual-Mode Multimodal Ranking model (DM2RM), which enables images of both the target objects and receptacles to be retrieved using a single model based on multimodal foundation models. We introduce a switching mechanism that leverages a mode token and phrase identification via a large language model to switch the embedding space based on the prediction target. To evaluate the DM2RM, we construct a novel dataset including real-world images collected from hundreds of building-scale environments and crowd-sourced instructions with referring expressions. The evaluation results show that the proposed DM2RM outperforms previous approaches in terms of standard metrics in image retrieval settings. Furthermore, we demonstrate the application of the DM2RM on a standardized real-world DSR platform including fetch-and-carry actions, where it achieves a task success rate of 82% despite the zero-shot transfer setting.